Variational autoencoder (VAE)
Variational autoencoders are a combination of three things:
1. Autoencoders
2. Variational Approximation & Variational Lower Bound
3. "Reparameterization" Trick
1. Autoencoders
Autoencoders are used to extract features from unlabeled training data. They are new methods for dimensionality reduction and part of neural networks branch.
Note: autoencoders can be used to replace older dimensionality reduction methods such as PCA for several reasons:
- For very large data sets that can’t be stored in memory, PCA will not be able to be performed. The autoencoder construction using keras can easily be batched resolving memory limitations.
- PCA is restricted to linear separation while autoencoders are capable of modelling complex non linear functions.

Learning can be done using a loss function such as $||x - \widehat{x}||^2$. In a similar way than neural network, optimization is typically done with backpropagation.
2. Variational Approximation & Variational Lower Bound
We assume $x$ is generated from unobserved (latent) $z$:
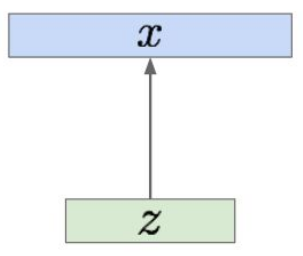
Practical example: $x$ can be seen as images and $z$ as the main attributes (orientation, colors, etc.)
$x \sim p_{\theta^}(x | z)$ where $p_{\theta^}(x | z)$ is called true conditional
$z \sim p_{\theta^}(z)$ where $p_{\theta^}(z)$ is called true prior
Objective: estimating $p_{\theta}(x)$. We thus need to estimate $\theta^*$.
We can do it through maximum likelihood. The marginal density is $p_{\theta}(x) = \int p_{\theta}(x|z) p_{\theta}(z) dz$
Note: a marginal likelihood function is a likelihood function in which some parameter variables have been marginalized. Marginalization consists in summing over the possible values of one variable in order to determine the contribution of another. E.g., $\mathbb{P}(X)=\Sigma_y \mathbb{P}(X, Y=y)$ or in continuous probabilities $p(x)=\int p(x, y) dy$. Also, if we don’t know the joint probability, we can express this using conditional probabilities: $p(x)=\int p(x | y) p(y) dy$
Problem: impossible to compute $p(x|z)$ for every $z$ ([computationally too expensive]{style=”color: orange”}) => problem is said intractable
| Solution: use another encoder learning $q_\phi (z | x)$ that approximates |
| $p_\theta(z | x)$ |
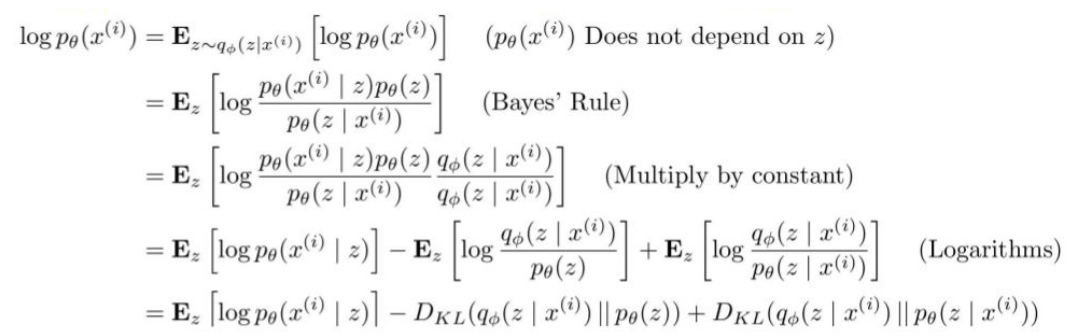
$\mathbb{E}z[\log p\theta (x^{(i)} | z]$: we can estimate this term through sampling
| $D_{KL}(q_\phi(z | x^{(i)}) | p_\theta(z))$: differentiable term |
$D_{KL}(q_\phi(z | x^{(i)}) || p_\theta(z | x^{(i)}))$: $p(z|x)$ intractable but we know that $D_{KL} \geq 0$
Let $\mathcal{L}(x^{(i)}, \theta, \phi) = \mathbb{E}z[\log p\theta (x^{(i)} | z] - D_{KL}(q_\phi(z | x^{(i)}) || p_\theta(z))$ = tractable lower bound that we can optimize
We know that $p_\theta (x^{(i)}) \geq \mathcal{L}(x^{(i)}, \theta, \phi)$ since $D_{KL}(q_\phi(z | x^{(i)}) || p_\theta(z | x^{(i)})) \geq 0$
Thus the maximum likelihood problem becomes: $\theta^, \phi^ = argmax_{\theta, \phi} \Sigma_{i=1}^N \mathcal{L}(x^{(i)}, \theta, \phi)$
We can minimize $D_{KL}(q_\phi(z | x^{(i)}) || p_\theta(z))$ making posterior distribution close to prior. To do so, we make encoder network predicting $\mu_{z | x}$ and $\Sigma_{z | x}$ and then we sample $z | x \sim \mathcal{N}(\mu_{z | x}, \Sigma_{z | x})$
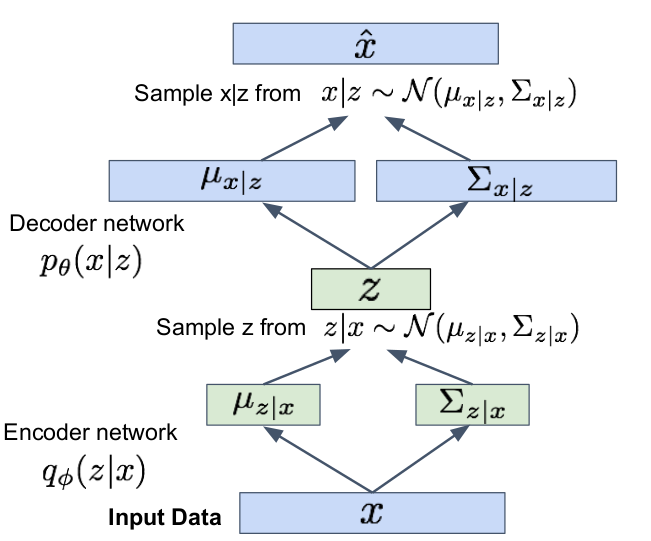
Problem: sampling $z | x \sim \mathcal{N}(\mu_{z | x}, \Sigma_{z | x})$ and $x | z \sim \mathcal{N}(\mu_{x | z}, \Sigma_{x | z})$ is not differentiable ([why?]{style=”color: orange”}).
=> we use reparametrization trick: we sample $z_0 \sim \mathcal{N}(0,1)$ to have $z = \mu_{x | z} + z_0 \Sigma_{x | z} \sim \mathcal{N}(\mu_{x | z}, \Sigma_{x | z})$
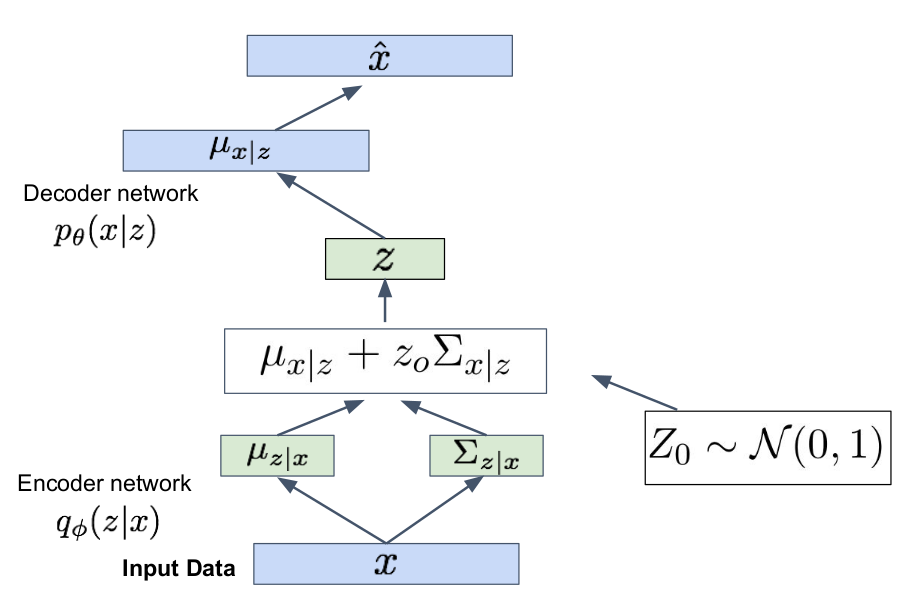
Optimization through forward and backward propagation!